텍스트 벡터화?
- 텍스트를 숫자형 벡터로 변환하는 전처리 과정
- 딥러닝 모델은 숫자형 자료만 처리
방법
텍스트 → 단어 → 단어 벡터 변환
텍스트 → 문자 → 문자 벡터 변환
텍스트 → N-gram(단어나 문자 그룹) → N-gram 벡터 변환
* N-gram : 연속된 단어나 문자의 그룹 단위 (텍스트 에서 단어나 문자를 하나 씩 이동하면서 추출)
벡터 변환 방법 (토큰 → 숫자형 벡터 변환)

| 원-핫 인코딩 (희소행렬) | 단어 임베딩 (밀집행렬) | |
| 정의 | 데이터를 수많은 0과 한개의 1로 구별 벡터 또는 행렬(matrix)의 값이 대부분 0으로 표현되는 희소 행렬(sparse matrix) |
단어의 의미를 고려하여 좀 더 조밀한 차원에 단어를 벡터로 표현 적은 차원으로 더 많은 정보를 저장하는 밀집행렬(Dense matrix) |
| 특징 | 1) 인코딩 방식 쉽고, 표현 방법 단순 2) 단어가 많은 경우 고차원 (단어수=차원수) |
1) 벡터의 차원을 단어 집합의 크기로 표현하지 않고, 사용자가 설정한 값(64, 128, 256, … 1024)으로 단어 벡터의 차원이 결정 (이 과정에서 0과 1의 값이 실수값으로 된다.) 2) 밀집벡터의 값은 딥러닝의 최적화 알고리즘으로 학습되어 만들어짐 |
| 표현방법 | 수동 | 훈련데이터로 학습 |
| 문제점 개선점 |
단어의 의미를 전혀 고려하지 않으며 벡터의 길이가 총 단어 수가 되므로 매우 희박(sparse)한 형태가 됨 행렬의 많은 값이 0이 되면서 공간적 낭비 |
더 적은 데이터로도 학습된 임베딩을 사용하여 높은 성능을 낼 수 있다 |
| 종류 | LSA, Word2Vec, GloVe, FastText 등 |
원-핫 벡터 VS 단어 임베딩 벡터
- 전체 문장 : 5574, 전체 단어 크기 : 8630 일 때

지도학습을 위한 특징 추출
data 입력 (label) -> Features 추출 (0 or 1) -> 알고리즘 -> model
TF-IDF (Term Frequency - Inverse Document Frequency) 가중치
정보 검색과 텍스트 마이닝에서 이용하는가중치.
여러 문서로 이루어진 문서군이 있을 때 어떤 단어가 특정 문서 내에서 얼마나 중요한 것인지를 나타내는 통계적 수치
ex) 스팸(spam) 메일분류기 생성을 위해서 model에 입력할 text자료를 문서 대비 단어의 출현 비율로 가중치를 적용하여 희소행렬을 만들고, 이를model의 입력으로 이용
one_hot_encoding = token.texts_to_matrix(texts, mode='tfidf')
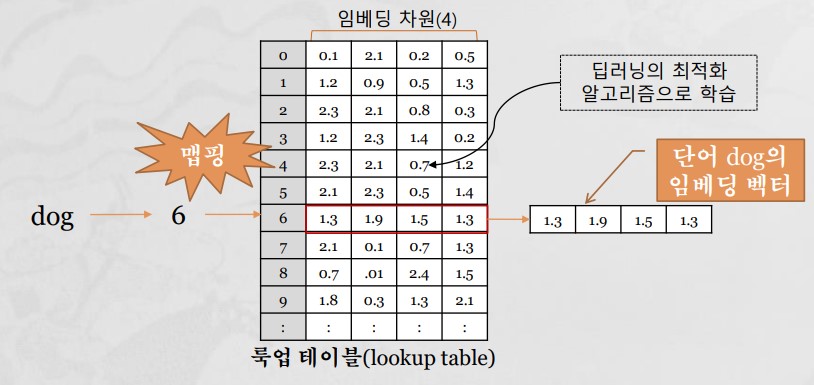
단어 임베딩 처리 과정
단어 → 단어 고유 정수 → 임베딩 층 → 임베딩 벡터
임베딩 층 입력으로 사용될 입력 시퀀스의 각 단어들은 모두 정수 인덱스 변환
{'the' : 1, 'cat' : 2, 'sat' : 3, 'on' : 4, 'mat' : 5, 'dog' : 6, 'ate' : 7, 'my' : 8, 'homework' : 9, … } 일 때,
vectorzing
작업절차
단계1 : 토큰(token) 생성 : 텍스트 -> 단어 추출
단계2 : 단어순서 인덱스 : 단어 -> 고유숫자(단어 역할)
단계3 : 패딩(padding) : 각 문장의 단어 길이 맞춤(maxlen 기준)
단계4 : 인코딩(encoding) : 딥러닝 모델에 공급할 자료(숫자형 벡터)
from tensorflow.keras.preprocessing.text import Tokenizer #토큰 생성기 from tensorflow.keras.preprocessing.sequence import pad_sequences #패딩 from tensorflow.keras.utils import to_categorical #one-hot encoding
text_sample.txt 참고
texts = ['The dog sat on the table.', 'The dog is my Poodle.']
토큰 생성기
tokenizer = Tokenizer()
단계1 : 토큰(token) 생성
tokenizer.fit_on_texts(texts) token = tokenizer.word_index #토큰 반환 print(token) #{'word':고유숫자} : 고유숫자 -> 단어 순서 색인 ''' {'the': 1, 'dog': 2, 'sat': 3, 'on': 4, 'table': 5, 'is': 6, 'my': 7, 'poodle': 8} ''' print('전체 단어 길이 =', len(token)) #전체 단어 길이 = 8
단계2 : 단어순서 인덱스 -> 정수변환(단어 순서 인덱스)
seq_vector = tokenizer.texts_to_sequences(texts) print(seq_vector) ''' [[1, 2, 3, 4, 1, 5], [1, 2, 6, 7, 8]] '''
단계3 : 패딩(padding) : maxlen 기준
lens = [len(sent) for sent in seq_vector] maxlen = max(lens) print(maxlen) #6max length : 최대 단어수 지정
ex) max_len = 10 : 모든 문장의 단어 10개 맞춤
-> 부족한 문장 0으로 채움
-> 초과단어 10개 짤림
padding = pad_sequences(seq_vector, maxlen=maxlen) print(padding) ''' [[1 2 3 4 1 5] - 6개 [0 1 2 6 7 8]] - 6개 '''
단계4 : 인코딩(encoding) : one-hot encoding(2진수)
one_hot = to_categorical(padding) print(one_hot)[[[0. 1. 0. 0. 0. 0. 0. 0. 0.] - the
[0. 0. 1. 0. 0. 0. 0. 0. 0.] - dog
[0. 0. 0. 1. 0. 0. 0. 0. 0.] - sat
[0. 0. 0. 0. 1. 0. 0. 0. 0.] - on
[0. 1. 0. 0. 0. 0. 0. 0. 0.] - the
[0. 0. 0. 0. 0. 1. 0. 0. 0.]]- table
[[1. 0. 0. 0. 0. 0. 0. 0. 0.] - padding
[0. 1. 0. 0. 0. 0. 0. 0. 0.] - the
[0. 0. 1. 0. 0. 0. 0. 0. 0.] - dog
[0. 0. 0. 0. 0. 0. 1. 0. 0.] - is
[0. 0. 0. 0. 0. 0. 0. 1. 0.] - my
[0. 0. 0. 0. 0. 0. 0. 0. 1.]]]-Poodle
one_hot.shape #(2, 6, 9) - (문자수, 단어수, 전체단어수+1)
feature extract
1. 텍스트 -> 특징(feature) 추출
-> texts -> 희소행렬(sparse matrix) : 딥러닝 모델 공급 data
-> 가중치 방법 : 출현여부, 출현빈도, 비율, tf*idf(단어출현빈도 * 1/문서출현)
2. num_words
- 희소행렬의 차수 지정(단어 개수)
ex) num_word=500 : 전체 단어에서 중요 단어 500개 선정
from tensorflow.keras.preprocessing.text import Tokenizer #토큰 생성기
text_sample.txt 참고
texts = ['The dog sat on the table.', 'The dog is my Poodle.']
토큰 생성기
tokenizer = Tokenizer()
단계1 : 토큰(token) 생성
tokenizer.fit_on_texts(texts) token = tokenizer.word_index #토큰 반환 print(token) #{'word':고유숫자} : 고유숫자 -> 단어 순서 색인 ''' {'the': 1, 'dog': 2, 'sat': 3, 'on': 4, 'table': 5, 'is': 6, 'my': 7, 'poodle': 8} ''' print('전체 단어 길이 =', len(token)) # 전체 단어 길이 = 8
1. 희소행렬(sparse matrix) : texts -> 특징 추출
1) 단어 출현여부
binary_mat = tokenizer.texts_to_matrix(texts=texts, mode='binary') print(binary_mat) # DTM ''' [[0. 1. 1. 1. 1. 1. 0. 0. 0.] [0. 1. 1. 0. 0. 0. 1. 1. 1.]] ''' binary_mat.shape #(2, 9) - (docs, words+1)
2) 단어 출현빈도
count_mat = tokenizer.texts_to_matrix(texts=texts, mode='count') print(count_mat) ''' [[0. 2. 1. 1. 1. 1. 0. 0. 0.] - the : 2 [0. 1. 1. 0. 0. 0. 1. 1. 1.]] '''
3) 단어 출현비율
freq_mat = tokenizer.texts_to_matrix(texts=texts, mode='freq') print(freq_mat)[[0. 0.33333333 0.16666667 0.16666667 0.16666667 0.16666667
0. 0. 0. ]
[0. 0.2 0.2 0. 0. 0.
0.2 0.2 0.2 ]]
the = 0.3333
2/6 #0.3333333333333333
dog = 0.1666
1/6
4) 단어 출현비율 : tf * idf(전체문서수/단어포함된문서수)
tfidf_mat = tokenizer.texts_to_matrix(texts=texts, mode='tfidf') print(tfidf_mat) #the : 0.8649 -> 0.510[[0. 0.86490296 0.51082562 0.69314718 0.69314718 0.69314718
0. 0. 0. ]
[0. 0.51082562 0.51082562 0. 0. 0.
0.69314718 0.69314718 0.69314718]]
tf = 0.333 tf * (2/1) #0.666 tf * (2/2) #0.333
2. num_words : 희소행렬 단어 길이 제한
토큰 생성기
tokenizer = Tokenizer(num_words=6) #5개 단어 선정(단어길이+1) tokenizer.fit_on_texts(texts) #텍스트 반영 tfidf_max = tokenizer.texts_to_matrix(texts, mode='tfidf') print(tfidf_max) ''' [[0. 0.86490296 0.51082562 0.69314718 0.69314718 0.69314718] [0. 0.51082562 0.51082562 0. 0. 0. ]] ''' tfidf_max.shape #(2, 6) - (docs, words+1)
feature classifier
- 희소행렬(인코딩) + DNN model
<작업절차>
1. csv file read
2. texts, label(0 or 1) 전처리
3. num_words = 4000 제한
4. texts -> sparse matrix : feature 추출
5. train/val split
6. DNN model
import pandas as pd #csv file rad import numpy as np #list -> array import string #texts 전처리 from sklearn.model_selection import train_test_split from tensorflow.keras.preprocessing.text import Tokenizer #토큰 생성기 #DNN model from tensorflow.keras.models import Sequentialb #model from tensorflow.keras.layers import Dense #layer path = r'C:\ITWILL\5_Tensorflow\workspace\chap08_TextVectorizing_RNN\data'
1. csv file read
spam_data = pd.read_csv(path + '/temp_spam_data2.csv', header = None) spam_data.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5573 entries, 0 to 5572
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 0 5574 non-null object - label(ham/spam) : y변수
1 1 5574 non-null object - texts : x변수
label = spam_data[0] texts = spam_data[1] label.value_counts()ham 4827 -> 0
spam 747 -> 1
texts
2. texts, label(0 or 1) 전처리
1) label 전처리
label = [1 if lab=='spam' else 0 for lab in label] #list + for label[:10] # [0, 0, 1, 0, 0, 1, 0, 0, 1, 1]
list -> numpy
label = np.array(label) label.shape # (5574,)
2) texts 전처리
def text_prepro(texts): #text_sample.txt 참고 #Lower case texts = [x.lower() for x in texts] #Remove punctuation texts = [''.join(c for c in x if c not in string.punctuation) for x in texts] #Remove numbers texts = [''.join(c for c in x if c not in string.digits) for x in texts] #Trim extra whitespace texts = [' '.join(x.split()) for x in texts] return texts
함수 호출 : texts 전처리
texts = text_prepro(texts) print(texts)
3. num_words = 4000 제한
tokenizer = Tokenizer() #전체 단어 이용 희소행렬 생성 tokenizer.fit_on_texts(texts) #텍스트 반영 words = tokenizer.index_word #단어 반환 print(words) print('전체 단어 수 : ', len(words)) #전체 단어 수 : 8629
4. Sparse matrix : feature 추출
x_data = tokenizer.texts_to_matrix(texts, mode='tfidf') x_data.shape # (5574, 8630) - (docs, words+1)
5. train_test_split : 80 vs 20
x_train, x_val, y_train, y_val = train_test_split( x_data, label, test_size=0.2) x_train.shape #(4459, 8630) x_val.shape #(1115, 8630) y_train.shape #(4459,) y_val.shape #(1115,)
6. DNN model
model = Sequential() input_shape = (8630,)
hidden layer1 : w[8630, 64]
model.add(Dense(units=64, input_shape=input_shape, activation='relu')) #1층
hidden layer2 : w[64, 32]
model.add(Dense(units=32, activation='relu')) #2층
output layer : 이항분류기
model.add(Dense(units=1, activation='sigmoid')) #3층 model.summary()_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_2 (Dense) (None, 64) 552384=[8630*64]+64
_________________________________________________________________
dense_3 (Dense) (None, 32) 2080=[64*32]+32
_________________________________________________________________
dense_4 (Dense) (None, 1) 33=[32*1]+1
=================================================================
Total params: 554,497
Trainable params: 554,497
7. model compile : 학습과정 설정
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
8. model training
model.fit(x=x_train, y=y_train, #훈련셋 epochs=10, #반복학습 횟수 verbose=1, #출력여부 validation_data= (x_val, y_val)) #검증셋
9. model evaluation
print('='*30) model.evaluate(x=x_val, y=y_val) #0s 1ms/step - loss: 0.1051 - accuracy: 0.9874
word embedding
* feature classifier 참고
word embedding(인코딩) + DNN model
인코딩 : 텍스트 전처리 결과
1. 희소행렬
texts -> 희소행렬(인코딩) -> DNN model
2. 단어임베딩(밀집행렬)
texts -> 정수 색인 -> padding -> Embedding층(인코딩) -> DNN model
Embedding(input_dim, outpu_dim, input_length)
input_dim : 전체단어수+1
outpu_dim : 임베딩 벡터 차원(32, 63, ...)
import pandas as pd # csv file rad import numpy as np # list -> array import string # texts 전처리 from sklearn.model_selection import train_test_split from tensorflow.keras.preprocessing.text import Tokenizer #토큰 생성기 from tensorflow.keras.preprocessing.sequence import pad_sequences #[추가] 패딩
DNN model
from tensorflow.keras.models import Sequential #model from tensorflow.keras.layers import Dense, Embedding, Flatten #[추가] layer import time #time check path = r'C:\ITWILL\5_Tensorflow\workspace\chap08_TextVectorizing_RNN\data'
1. csv file read
spam_data = pd.read_csv(path + '/temp_spam_data2.csv', header = None) spam_data.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5573 entries, 0 to 5572
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 0 5574 non-null object - label(ham/spam) : y변수
1 1 5574 non-null object - texts : x변수
label = spam_data[0] texts = spam_data[1] label.value_counts() ''' ham 4827 -> 0 spam 747 -> 1 ''' texts
2. texts, label(0 or 1) 전처리
1) label 전처리
label = [1 if lab=='spam' else 0 for lab in label] #list + for label[:10] # [0, 0, 1, 0, 0, 1, 0, 0, 1, 1]
list -> numpy
label = np.array(label) label.shape # (5574,)
2) texts 전처리
def text_prepro(texts): #text_sample.txt 참고 #Lower case texts = [x.lower() for x in texts] #Remove punctuation texts = [''.join(c for c in x if c not in string.punctuation) for x in texts] #Remove numbers texts = [''.join(c for c in x if c not in string.digits) for x in texts] #Trim extra whitespace texts = [' '.join(x.split()) for x in texts] return texts
함수 호출 : texts 전처리
texts = text_prepro(texts) print(texts)
3. num_words = 4000 제한
tokenizer = Tokenizer() #전체 단어 이용 희소행렬 생성
tokenizer = Tokenizer(num_words = 4000) #2차 : 4000 단어 제한 tokenizer.fit_on_texts(texts) #텍스트 반영 words = tokenizer.index_word #단어 반환 print(words) print('전체 단어 수 : ', len(words)) #전체 단어 수 : 8629 input_dim = len(words) + 1 #전체단어수+1
4. Sparse matrix : feature 추출
x_data = tokenizer.texts_to_matrix(texts, mode='tfidf') x_data.shape # (5574, 8630) - (docs, words+1) -> (5574, 4000)
[추가] 4. 정수 색인 : 단어 순번
seq_result = tokenizer.texts_to_sequences(texts) print(seq_result) lens = [len(sent) for sent in seq_result] lens maxlen = max(lens) maxlen #158
[추가] 5.padding : maxlen 기준 단어길이 맞춤
x_data = pad_sequences(seq_result, maxlen=maxlen) x_data.shape #(5574, 158) - (문장수, 단어길이)
6. train_test_split : 80 vs 20
x_train, x_val, y_train, y_val = train_test_split( x_data, label, test_size=0.2) x_train.shape #(4459, 8630) x_val.shape #(1115, 8630) y_train.shape #(4459,) y_val.shape #(1115,)
7. DNN model
model = Sequential()
[추가] 8. Embedding layer : 1층 - 인코딩
model.add(Embedding(input_dim=input_dim, output_dim=32, input_length=maxlen))input_dim : 전체단어수+1
output_dim : 임베딩 벡터 차원(32, 64, ...)
input_length : 문장을 구성하는 단어길이(maxlen)
[추가] 2d -> 1d
model.add(Flatten())
hidden layer1 : w[4000, 64] vs w[32, 64]
model.add(Dense(units=64, activation='relu')) #2층
hidden layer2 : w[64, 32]
model.add(Dense(units=32, activation='relu')) #3층
output layer : 이항분류기
model.add(Dense(units=1, activation='sigmoid')) #4층 model.summary()_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_2 (Dense) (None, 64) 552384=[8630*64]+64
_________________________________________________________________
dense_3 (Dense) (None, 32) 2080=[64*32]+32
_________________________________________________________________
dense_4 (Dense) (None, 1) 33=[32*1]+1
=================================================================
Total params: 554,497
Trainable params: 554,497
start = time.time()'데이터분석가 과정 > Tensorflow' 카테고리의 다른 글
| DAY73. Tensorflow Text Vectorizing RNN (2) (0) | 2022.01.04 |
|---|---|
| DAY71. Tensorflow Face detection (2) (0) | 2021.12.30 |
| DAY70. Tensorflow Face detection (1)face landmark (0) | 2021.12.29 |
| DAY69. Tensorflow Selenium Crawling (0) | 2021.12.28 |
| DAY68. Tensorflow CNN model (2)ImageGenerator (0) | 2021.12.27 |