머신러닝이란?

딥 러닝을 포함하고 있는 개념
데이터가 주어지면, 기계가 스스로 데이터로부터 규칙성을 찾아냄
주어진 데이터로부터 규칙성을 찾는 과정을 훈련(training) 또는 학습(learning)이라고 함
머신러닝 모델의 평가
기계를 학습하기 전 해당 데이터를 훈련용, 검증용, 테스트용 세 가지로 분리
1. 훈련 데이터 : 머신 러닝 모델을 학습하는 용도
2. 테스트 데이터 : 학습한 머신 러닝 모델의 성능을 평가하기 위한 용도
3. 검증용 데이터 : 모델의 성능을 조정하기 위한 용도 (과적합(overfitting) 여부 판단, 하이퍼파라미터를 조정)
- 하이퍼파라미터(초매개변수) : 모델의 성능에 영향을 주는 사람이 값을 지정하는 변수
ex) 경사 하강법에서 학습률(learning rate), 딥러닝에서 뉴런의 수 또는 층의 수
- 매개변수 : 가중치와 편향. 학습을 하는 동안 값이 계속해서 변하는 수
모델이 학습하는 과정에서 얻어지는 값
훈련용 데이터로 훈련을 모두 시킨 모델은 검증용 데이터를 사용하여 정확도를 검증하고, 하이퍼파라미터를 튜닝(tuning)한다.
가중치(weight) = Learnable Parameters

수상돌기에 해당하는 외부 신경 자극 (=뉴런 간 연결 강도)
신경망이 훈련하는동안, update되어 weight가 변경됨
가중치 (w1, w2) : 시냅스에서 신호 세기 결정
- 신호 세기 = 가중치(w1, w2) : 중요 변수에 따라서 가중치가 달라짐
- x변수가 y에 주는 영향력을 나타내는 값
- 값이 클 수록 해당 변수가 더 중요하다는 의미(강한 신호를 y에 보낸다.)
출력(y) : 망의 총 합을 축색돌기로 통해서 받음
- y = (x1.w1) + (x2.w2)
편향(bias)
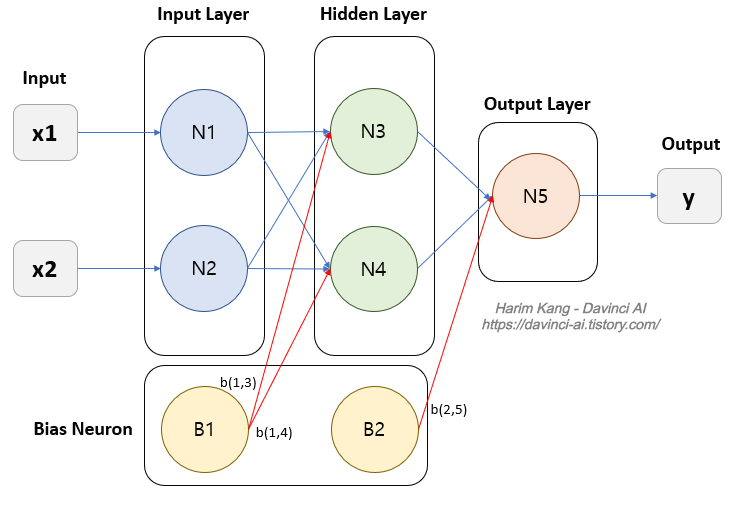
뉴런의 활성화를 조절하는 변수
* 2개 조절변수 1. 가중치(w) : x 변수의 중요도 2. 편향(b) : 뉴런의 활성화
- 활성(1)/비활성(0)의 임계치
- 망의 총합을 다음 계층으로 넘길 때 기준이 되는 값
- y = (x1.w1 + x2.w2) + b
- cf) 선형회귀방정식과 동일 : y = (a1.x1 + a2.x2) + b : (b : 상수)
지도 학습과 비지도 학습
1) 지도 학습(Supervised Learning)
레이블(Label =y, 실제값)이라는 정답과 함께 학습하는 것
자연어 처리는 대부분 지도학습에 속함
2) 비지도 학습(Unsupervised Learning)
데이터에 별도의 레이블이 없이 학습하는 것 ex) LSA, LDA
3) 자기지도 학습(Self-Supervised Learning, SSL)
레이블이 없는 데이터가 주어지면, 모델이 학습을 위해서 스스로 데이터로부터 레이블을 만들어서 학습하는 경우 ex) Word2Vec, BERT
혼동 행렬(Confusion Matrix)
정확도(Accuracy) : 맞춘 문제수를 전체 문제수로 나눈 값
정확도는 맞춘 결과와 틀린 결과에 대한 세부적인 내용을 알려주지는 않으므로, 이를 위해 사용하는 것이 혼동 행렬(Confusion Matrix)
True Positive(TP) : 실제 True인 정답을 True라고 예측 (정답)
False Positive(FP) : 실제 False인 정답을 True라고 예측 (오답)
False Negative(FN) : 실제 True인 정답을 False라고 예측 (오답)
True Negative(TN) : 실제 False인 정답을 False라고 예측 (정답)
1) 정밀도(Precision) : 모델이 True라고 분류한 것 중에서 실제 True인 것의 비율
2) 재현율(Recall) : 실제 True인 것 중에서 모델이 True라고 예측한 것의 비율
* 두 식 모두 분자가 TP
3) 정확도(Accuracy) : 전체 예측한 데이터 중에서 정답을 맞춘 것에 대한 비율
실질적으로 더 중요한 경우에 대한 데이터가 전체 데이터에서 너무 적은 비율을 차지한다면 정확도는 좋은 측정 지표가 될 수 없다. 이 경우에는 F1-Score1 사용.
ex) 200일중 6일 비가 왔고, 비 오는 날 예측 모델이 200일 내내 맑았다고 예측하면 정확도는 97. 그러나 비 내리는 날은 하나도 못 맞추었다.
과적합(Overfitting)
훈련 데이터를 과하게 학습한 경우
훈련 데이터에 대해서만 과하게 학습하면 성능 측정을 위한 데이터인 테스트 데이터나 실제 서비스에서는 정확도가 좋지 않은 현상이 발생
훈련 데이터에 대한 정확도는 높지만, 테스트 데이터는 정확도가 낮은 상황
해결법 : 테스트 데이터의 오차가 증가하기 전이나, 정확도가 감소하기 전에 훈련을 멈추는 것
과소 적합(Underfitting)
테스트 데이터의 성능이 올라갈 여지가 있음에도 훈련을 덜 한 상태
훈련 자체가 부족한 상태이므로 훈련 횟수인 에포크가 지나치게 적으면 발생
훈련 데이터에 대해서도 정확도가 낮다
과적합 방지를 고려한 일반적인 딥 러닝 모델의 학습 과정
Step 1. 주어진 데이터를 훈련 데이터, 검증 데이터, 테스트 데이터로 나눈다. 가령, 6:2:2 비율로 나눌 수 있다.
Step 2. 훈련 데이터로 모델을 학습한다. (에포크 +1)
Step 3. 검증 데이터로 모델을 평가하여 검증 데이터에 대한 정확도와 오차(loss)를 계산한다.
Step 4. 검증 데이터의 오차가 증가하였다면 과적합 징후이므로 학습 종료 후 Step 5로 이동, 아니라면 Step 2.로 재이동한다.
Step 5. 모델의 학습이 종료되었으니 테스트 데이터로 모델을 평가한다.
'개인공부 > Tensorflow' 카테고리의 다른 글
| 89. 딥러닝 기초 이론 (2)회귀와 분류 (0) | 2021.12.24 |
|---|---|
| 88. Tensorflow Keras model 연습문제 (0) | 2021.12.23 |
| 86. Tensorflow Classification 연습문제 (0) | 2021.12.21 |
| 85. Tensorflow LinearRegression 연습문제 (0) | 2021.12.20 |
| 81. Tensorflow Basic 연습문제 (0) | 2021.12.15 |