앙상블(Ensemble) 모델
여러 개의 분류기(Classifier)를 생성하고, 각 예측 결과를 결합하여 예측력을 향상시키는 모델
장점 : 단일 모델(Decision Tree)에 비해서 분류 성능 우수
단일 Tree vs 앙상블 모델
| Decision tree | Random Forest |
| 생성된 분류모델을 검정데이터에 적용하여 목표변수 예측 | 동일한 하나의 데이터 집합에서 임의복원 샘플링을 통해 여러 개의 훈련용 데이터를 생성 |
| 생성된 분류모델을 검정데이터에 적용하여 목표변수 예측 | 여러 번의 학습을 통해 여러 개의 트리 생성하고, 이를 결합하여 최종적으로 목표변수 예측 |
| 생성된 분류모델을 검정데이터에 적용하여 목표변수 예측 | 분류모델을 검정데이터에 적용 |
앙상블(Ensemble) 알고리즘
종류 : 배깅(Bagging), 부스팅(Boosting)
앙상블 학습 모델 생성 절차 :
1. 전체 데이터에서 훈련 집합 생성
2. 각 훈련집합 모델 학습
3. 학습된 모델 앙상블 도출
* 단점 : 모델 결과의 해석이 어렵고, 예측 시간 많이 소요
앙상블 모델 학습 알고리즘 비교
| 배깅(Bagging) | 부스팅(Boosting) | |
| 공통점 | 전체 데이터 집합으로부터 복원 랜덤 샘플링(bootstrap) 으로 훈련 집합 생성 | |
| 차이점 | 병렬학습 : 각 모델의 결과 를 조합하여 투표 결정 | 순차학습 : 현재 모델 가중치 -> 다음 모델 전달 |
| 특징 | 균일한 확률분포에 의해서 훈련 집합 생성 | 분류하기 어려운 훈련 집합 생성 |
| 강점 | 과대적합에 강함 | 높은 정확도 |
| 약점 | 특정 영역 정확도 낮음 | Outlier 취약 |
| R 패키지 | randomForest | XGboost |
앙상블 학습 알고리즘
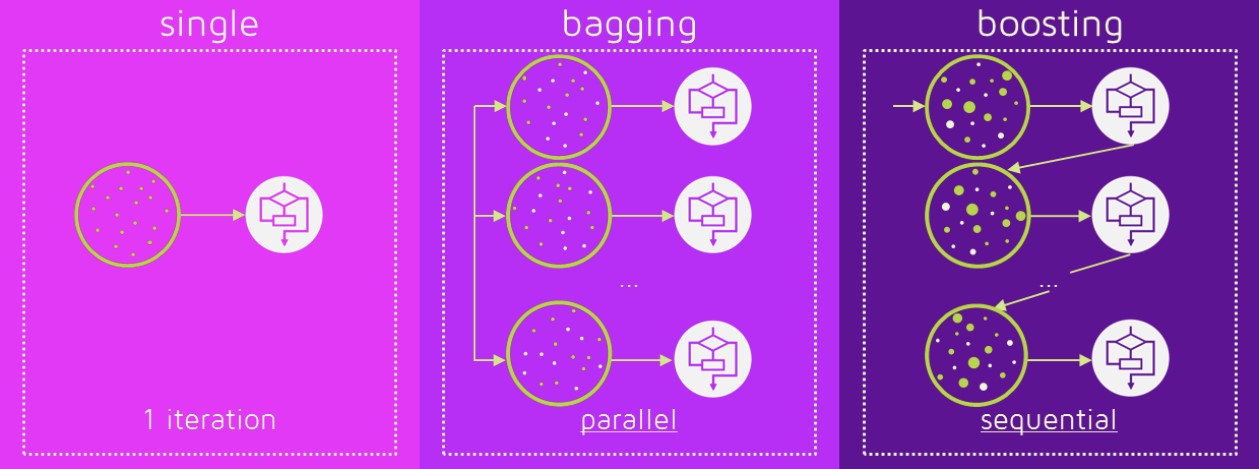
* Bagging은 일반적인 모델을 만드는데 집중, Boosting은 맞추기 어려운 문제를 맞추는데 초점을 맞춤 앙상블 학습 방법
1) 부트스트랩(Bootstrap)
앙상블 모델에서 원래의 데이터 셋으로부터 복원 추출방식으로 훈련 데이터 셋을 생성하는 기법
데이터의 양을 임의적으로 늘리고, 데이터셋의 분포가 고르지 않을 때 고르게 만드는 효과
2) 배깅 알고리즘
Bagging : Bootstrap Aggregating(“주머니 통합”)
부트스트랩을 통해서 조금씩 서로 다른 훈련 데이터를 생성하여 모델 (훈련 된 트리)을 생성하고, 결과를 결합(aggregating) 시키는 방법
3) 부스팅(boosting) 알고리즘
잘못 분류된 객체들에 집중하여 새로운 분류규칙을 생성하는 단계를 반복하는 알고리즘(순차적 학습)
약한 예측모형들을 결합하여 강한 예측모형을 만드는 알고리즘
오 분류된 개체는 높은 가중치, 정 분류된 개체는 낮은 가중치를 적용하여 예측모형의 정확도를 향상시키기 위한 방법
4) RandomForest
배깅 알고리즘과 유사함(앙상블 모델)
회귀분석, 분류분석 모두 가능
별도 튜닝(스케일 조정) 과정 없음
단일 tree 모델 단점 보완(성능, 과대적합)
대용량 데이터 셋으로 처리시간 증가(단점)
멀티코어 프로세스 이용 병렬처리 가능
차이점
배깅 : 샘플 복원 추출 시 모든 독립변수(설명변수) 사용
랜덤포레스트 : a개 독립변수(설명변수)만으로 복원 추출
설명변수 개수 : sqrt(설명변수 개수) (예: 15개 변수라면 4개 정도)
설명변수가 많을 경우 변수간 상관성이 높은 변수가 섞일 확률 제거
5) XGBoost 알고리즘
여러 개의 결정 트리를 임의적으로 학습하는 방식. 앙상블 학습방법(부스팅 유형
순차적 학습 방법 : 약한 분류기를 강한 분류기로 생성. 분류정확도 우수, Outlier 취약
[실습]
RandomForest
from sklearn.ensemble import RandomForestClassifier #질적변수
from sklearn.datasets import load_wine #3개 class
from sklearn.metrics import confusion_matrix, accuracy_score, classification_report #model 평가도구
1. dataset load
wine = load_wine()
x변수 이름
x_names = wine.feature_names
x_names
len(x_names) #13
X, y = load_wine(return_X_y = True)
2. model 생성
model = RandomForestClassifier().fit(X = X, y = y) #기본 파라미터
3. test set 생성
import numpy as np
idx = np.random.choice(a = len(X), size = 100, replace = False)
idx
X_test, y_test = X[idx], y[idx]
X_test.shape #(100, 13)
y_test.shape #(100,)
4. model 평가
y_pred = model.predict(X = X_test)
con_mat = confusion_matrix(y_test, y_pred)
print(con_mat)[[33 0 0]
[ 0 43 0]
[ 0 0 24]]
acc = accuracy_score(y_test, y_pred)
print(acc) #1.0
5. 중요변수 시각화 (y에 영향력이 가장 큰 중요변수 선정 )
dir(model) #model에서 호출가능한 method확인
model.feature_importances_ #prolinearray([0.11749764, 0.02167489, 0.0126863 , 0.02941608, 0.02915404,
0.05885703, 0.17041459, 0.01035685, 0.01737543, 0.15155433,
0.08574004, 0.1037657 , 0.19150708])
x_names[-1] #'proline'
x_names[6] #'flavanoids'
가로막대 차트
import matplotlib.pyplot as plt
plt.barh(range(13), width = model.feature_importances_)
13개의 눈금마다 x변수 이름을 붙이기
plt.yticks(range(13), x_names)
plt.xlabel('feature_importances')
plt.show()
RandomForest GridSearch
1. RandomForest
2. GridSearch : best parameters
from sklearn.ensemble import RandomForestClassifier #model
from sklearn.datasets import load_digits #10개 class
from sklearn.model_selection import GridSearchCV #best params
1. dataset load
X, y = load_digits(return_X_y=True)
2. model 생성 : default params
model = RandomForestClassifier().fit(X = X, y = y)n_estimators : int, default=100 : 결정트리 개수
criterion : {"gini", "entropy"}, default="gini" : 중요변수 선정 기준
max_depth : int, default=None : 최대 트리 깊이
min_samples_split : int or float, default=2
min_samples_leaf : int or float, default=1
max_features : {"auto", "sqrt", "log2"} : 최대 사용할 x변수 개수
model.score(X = X, y = y)
3. GridSearch model
parmas = {'n_estimators' : [100, 150, 200],
'criterion' : ["gini", "entropy"],
'max_depth' : [None, 3, 5, 7],
'min_samples_leaf' : [1, 2, 3],
'max_features' : ["auto", "sqrt"]} #dict형
grid_model = GridSearchCV(model, param_grid=parmas,
scoring='accuracy', cv = 5, n_jobs= -1)
model2 = grid_model.fit(X = X, y = y)
dir(model2)
'''
'best_params_',
'best_score_',
'''model2.best_score_ #0.9438130609718354
print('best params : ', model2.best_params_)best params : {'criterion': 'gini',
'max_depth': None,
'max_features': 'sqrt',
'min_samples_leaf': 1,
'n_estimators': 150}
new model
new_model = RandomForestClassifier(
max_features='sqrt',n_estimators=150).fit(X = X, y = y)
new_model.score(X = X, y = y) #1.0
XGBoost_test
pip install xgboost
from xgboost import XGBClassifier #분류 Tree
from xgboost import plot_importance #중요변수 시각화
from sklearn.datasets import make_blobs #dataset : 방울. 선점도용
from sklearn.model_selection import train_test_split #split도구
from sklearn.metrics import accuracy_score, classification_report
1. dataset load
X, y = make_blobs(n_samples=2000, n_features=4, centers=2,
cluster_std=2.5, random_state=123)n_samples : 표본(=방울)의 개수 (기본 : 100)
n_features = x변수 개수
centers = y변수 class(=방울의 유형) 개수
cluster_std = 클러스터 간 표준편차(노이즈 발생), 데이터의 복잡도(기본:1)
2. train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
3. model 생성 : 이항분류기(centers=2)
model = XGBClassifier(Objective = "binary:logistic").fit(X = X, y = y, eval_metric = 'error')활성함수(activeation function) : model예측값 -> 출력 y로 활성화
Objective = "binary:logistic" : 이항분류기 - sigmoid함수
Objective = "multi:softprob" : 다향분류기 - softmax함수
4. model 평가 (분류정확도)
y_pred = model.predict(X = X_test)
len(y_pred)
len(y_test)
acc = accuracy_score(y_test, y_pred)
print(acc) #1.0
5. 중요변수 시각화
fscore = model.get_booster().get_fscore()
print(fscore)
plot_importance(model)
XGBoost_boston
회귀트리 : y변수 양적변수(비율척도)
분류트리 : y변수 질적변수(명목척도)
from xgboost import XGBRegressor #회귀트리 모델
from xgboost import plot_importance #중요변수 시각화
from sklearn.datasets import load_boston #dataset
from sklearn.model_selection import train_test_split #split
from sklearn.metrics import mean_squared_error, r2_score #평가
1. dataset load
boston = load_boston()
x_names = boston.feature_names #x변수 이름
print(x_names)['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO'
'B' 'LSTAT']
X = boston.data
y = boston.target
X.shape #(506, 13)
type(X) #numpy.ndarray
y #연속형(비율척도)
2. dataset split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3)
3. model 생성
model = XGBRegressor().fit(X=X_train, y=y_train)
4. 중요변수 확인
fscore = model.get_booster().get_fscore()
print(fscore){'f0': 698.0, 'f1': 43.0, 'f2': 107.0, 'f3': 23.0, 'f4': 140.0, 'f5': 410.0, 'f6': 361.0, 'f7': 337.0, 'f8': 36.0, 'f9': 60.0, 'f10': 77.0, 'f11': 313.0, 'f12': 311.0}
plot_importance(model) #1 > 6 > 7
x_names[0] #'CRIM'
x_names[5] #'RM'
x_names[6] #'AGE'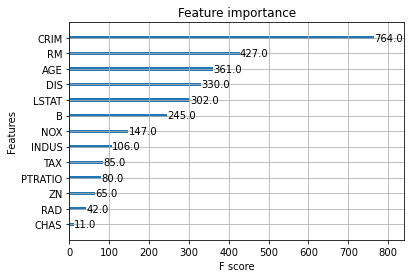
5. model 평가
y_pred = model.predict(X = X_test)
1) MSE : y변수 로그변환 or 정규화(o)
mse = mean_squared_error(y_test, y_pred)
print(mse) #11.779651544177534
2) 결정계수(r^2) : y변수 로그변환 or 정규화(x)
score = r2_score(y_test, y_pred)
print(score) #0.8240142993822802
중요변수 시각화에서 X변수명 표시
import pandas as pd
1. numpy -> DataFrame 변환
X = boston.data
X.shape #(506, 13)
y = boston.target
df = pd.DataFrame(X, columns=x_names)
df.info()
칼럼 추가
df['target'] = y
df.info()
x,y변수 선정
cols = list(df.columns)
X = df[cols[:-1]]
y = df['target']
2. dataset split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3)
3. model 생성
model = XGBRegressor().fit(X=X_train, y=y_train)
4. 중요변수 확인
fscore = model.get_booster().get_fscore()
print(fscore)
plot_importance(model)
5. model 평가
y_pred = model.predict(X = X_test)
1) MSE : y변수 로그변환 or 정규화(o)
mse = mean_squared_error(y_test, y_pred)
print(mse) # 11.779651544177534
2) 결정계수(r^2) : y변수 로그변환 or 정규화(x)
score = r2_score(y_test, y_pred)
print(score) # 0.8240142993822802
6. model save & load
model #object
import pickle #binary file
model save
pickle.dump(model, open('xgb_model.pkl', mode='wb'))
model load
load_model = pickle.load(open('xgb_model.pkl', mode='rb'))
y_pred = load_model.predict(X = X_test) #new_data
score = r2_score(y_test, y_pred)
print(score) #0.8919146007745038
XGBoost GridSearch
1. XGBoost Hyper parameter : ppt.19
2. model 학습 조기 종료
3. Best Hyper parameter 찾기
from xgboost import XGBClassifier #model
from xgboost import plot_importance #중요변수 시각화
from sklearn.datasets import load_breast_cancer #이항분류 dataset
from sklearn.model_selection import train_test_split #split
from sklearn.metrics import accuracy_score, classification_report #평가
1. XGBoost Hyper parameter
1) dataset load
cancer = load_breast_cancer()
x_names = cancer.feature_names #x변수명
print(x_names, len(x_names)) #30
class_names = cancer.target_names #y변수 class명
print(class_names) #['malignant' 'benign']
X = cancer.data
y = cancer.target
2) dataset split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3)
3) model 생성
model = XGBClassifier().fit(X_train, y_train) #default 파라미터
print(model) #default 파라미터1. colsample_bytree=1 : 트리 모델 생성 시 훈련셋 샘플링 비율(보통 : 0.6 ~ 1)
2. learning_rate=0.3 : 학습율(보통 : 0.01~0.1) = 0의 수렴속도
3. max_depth=6 : 트리의 깊이(클 수록 성능이 좋아짐, 과적합 영향)
4. min_child_weight=1 : 자식 노드 분할을 결정하는 가중치(Weight)의 합
* 0~n값 지정 : 작을 수록 성능이 좋아짐, 과적합 영향
5. n_estimators=100 결정 트리 개수(default=100), 많을 수록 고성능
6. objective='binary:logistic'(이항분류기), 'multi:softprob'(다항분류기)
과적합 조절 : max_depth 작게, min_child_weight 높게 설정
2. model 학습 조기 종료
xgb = XGBClassifier(n_estimators=500) #object
model = xgb.fit(X = X_train, y = y_train, #훈련셋
eval_set = [ (X_test, y_test) ], #평가셋,
eval_metric = 'error', #평가 방법(오차)
early_stopping_rounds = 80, #기준 tree 개수
verbose = True) #학습과정 확인훈련셋 : X = X_train, y = y_train
평가셋 : (X_test, y_test)
평가방법 : 'error'
조기종료 라운드 수 : early_stopping_rounds
학습과정 콘솔 출력 : verbose = True
[91] validation_0-error:0.04094
4) model 평가
y_pred = model.predict(X = X_test)
acc = accuracy_score(y_test, y_pred)
print(acc) #0.9649122807017544
3. Best Hyper parameter 찾기
from sklearn.model_selection import GridSearchCV #class
1) 기본 model
model = XGBClassifier()
params = {'colsample_bytree' : [0.5, 0.7, 1],
'learning_rate' : [0.01, 0.3, 0.5],
'max_depth' : [5,6,7],
'min_child_weight' : [0.5,1,3],
'n_estimators' : [90, 100, 200]} #dict
2) grid search model
gs = GridSearchCV(estimator=model, param_grid=params, cv = 5)
grid_model = gs.fit(X_train, y_train)
3) best score & parameter
dir(grid_model)
grid_model.best_score_ #0.9649367088607596
grid_model.best_params_{'colsample_bytree': 0.7,
'learning_rate': 0.3,
'max_depth': 5,
'min_child_weight': 1,
'n_estimators': 200}
4) best model 생성
model = XGBClassifier(colsample_bytree=0.7,
learning_rate=0.3,
max_depth=5,
min_child_weight=1,
n_estimators=200).fit(X_train, y_train)
y_pred = model.predict(X = X_test)
acc = accuracy_score(y_test, y_pred)
print(acc) #0.9532163742690059
report = classification_report(y_test, y_pred)
print(report)
중요변수 시각화
plot_importance(model)
'데이터분석가 과정 > Python' 카테고리의 다른 글
| DAY56. Python TextMining (1)WebCrawling (url, tag, html) (0) | 2021.12.09 |
|---|---|
| DAY55. Python Cluster&Recommand (계층군집분석, KMeans, 추천시스템모형) (0) | 2021.12.08 |
| DAY53. Python TreeModel (1)DicisionTree (0) | 2021.12.06 |
| DAY52. Python Classification (2)TF-IDF sparse Matrix (단어 추출) (0) | 2021.12.03 |
| DAY51. Python Classification (1)Classification (문서 분류) (0) | 2021.12.02 |