개인공부/Python
106. 파이널 프로젝트 (12)네이버 리뷰 감성분석
LEE_BOMB
2022. 1. 15. 21:55
0. 모듈 임포트
%matplotlib inline
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import konlpy
import re
from konlpy.tag import Okt
from collections import Counter
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
1. 데이터 가져오기 & 결측치 제거
df = pd.read_csv(r"경로명\파일명.csv")
df.head()
df.shape #11450, 2
df.isnull().sum()score 0
review 104
dtype: int64
df = df.dropna(axis=0) #결측치 행 제거
df.shape #11346, 2
df.isnull().sum()score 0
review 0
dtype: int64
2. 데이터 전처리
def apply_regular_expression(review):
hangul = re.compile('[^ ㄱ-ㅣ 가-힣]') #한글 추출 규칙: 띄어 쓰기(1 개)를 포함한 한글
result = hangul.sub('', str(review)) #hangul규칙을 review에 적용(.sub)시킴
return result
apply_regular_expression(df['review'])
3. 형태소 분석 (명사 단위 추출)
okt = Okt() #명사 형태소 추출 함수
nouns = okt.nouns(apply_regular_expression(df['review'][0]))
nouns #['평점', '알바', '특', '내용', '얘기', '배우', '연기', '단말', '장창', '함']
corpus = "".join(df['review'].tolist()) #말뭉치 생성
corpus #부분출력
전체 형태소 분석
apply_regular_expression(corpus)
nouns = okt.nouns(apply_regular_expression(corpus))
print(nouns)
4. 전처리
#빈도 보기
counter = Counter(nouns)
counter.most_common(10)
#한 글자 명사 제거
available_counter = Counter({x: counter[x] for x in counter if len(x) > 1})
available_counter.most_common(10)
#불용어 제거
stopwords = pd.read_csv("https://raw.githubusercontent.com/yoonkt200/FastCampusDataset/master/korean_stopwords.txt").values.tolist()
stopwords[:10]
#불용어 사전에 추가하기
movie_stopwords = ['영화', '이제', '때문', '정도', '부분', '이것', '이거', '하다', '내가', '의해', '저희', '따라', '의해']
for word in movie_stopwords:
stopwords.append(word)
5. bow vector 생성
def text_cleaning(review):
hangul = re.compile('[^ ㄱ-ㅣ 가-힣]') #정규 표현식
result = hangul.sub('', review)
okt = Okt() #형태소 추출
nouns = okt.nouns(result)
nouns = [x for x in nouns if len(x) > 1] # 한글자 키워드 제거
nouns = [x for x in nouns if x not in stopwords] # 불용어 제거
return nouns
vect = CountVectorizer(tokenizer = lambda x: text_cleaning(x))
bow_vect = vect.fit_transform(df['review'].tolist())
word_list = vect.get_feature_names()
count_list = bow_vect.toarray().sum(axis=0)
word_list #단어 리스트
count_list #각 단어가 전체 리뷰중에 등장한 총 횟수
bow_vect.toarray() #각 단어의 리뷰별 등장 횟수
bow_vect.shape #(11346, 6489)
word_count_dict = dict(zip(word_list, count_list))
word_count_dict #"단어" - "총 등장 횟수" Matching
6. TF-IDF로 변환
tfidf_vectorizer = TfidfTransformer()
tf_idf_vect = tfidf_vectorizer.fit_transform(bow_vect)
print(tf_idf_vect.shape) #(11346, 6489)
print(tf_idf_vect[0]) #첫 번째 리뷰에서의 단어 중요도(TF-IDF값) -> 0이 아닌 것만 출력
#첫 번째 리뷰에서 모든 단어의 중요도 (0인 값까지 포함)
print(tf_idf_vect[0].toarray().shape) #(1, 6489)
print(tf_idf_vect[0].toarray()) #[[0. 0. 0. ... 0. 0. 0.]]
#벡터-단어 매핑
vect.vocabulary_
invert_index_vectorizer = {v: k for k, v in vect.vocabulary_.items()}
print(str(invert_index_vectorizer)[:100]+'...')
7. 감성분류 예측모델
df.sample(10)
df['score'].hist()
#1~6 부정적 7~10 긍정적 분류하여 1, 0 부여
def rating_to_label(score):
if score > 6:
return 1
else:
return 0
df['y'] = df['score'].apply(lambda x: rating_to_label(x))
df["y"].value_counts()1 8007
0 3339
훈련/검정set 나누기
x = tf_idf_vect
y = df['y']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state=1)
x_train.shape, y_train.shape #((7942, 6489), (7942,))
x_test.shape, y_test.shape #((3404, 6489), (3404,))
8. 모델 학습
#fit in training set
lr = LogisticRegression(random_state = 0)
lr.fit(x_train, y_train)
#predict in test set
y_pred = lr.predict(x_test)
#분류 결과 평가
print('accuracy: %.2f' % accuracy_score(y_test, y_pred)) #0.77
print('precision: %.2f' % precision_score(y_test, y_pred)) #0.77
print('recall: %.2f' % recall_score(y_test, y_pred)) #0.95
print('F1: %.2f' % f1_score(y_test, y_pred)) #0.85
#혼동행렬
from sklearn.metrics import confusion_matrix
confu = confusion_matrix(y_true = y_test, y_pred = y_pred)
plt.figure(figsize=(4, 3))
sns.heatmap(confu, annot=True, annot_kws={'size':15}, cmap='OrRd', fmt='.10g')
plt.title('Confusion Matrix')
plt.show()
10. 시각화
plt.figure(figsize=(10, 8))
plt.bar(range(len(lr.coef_[0])), lr.coef_[0])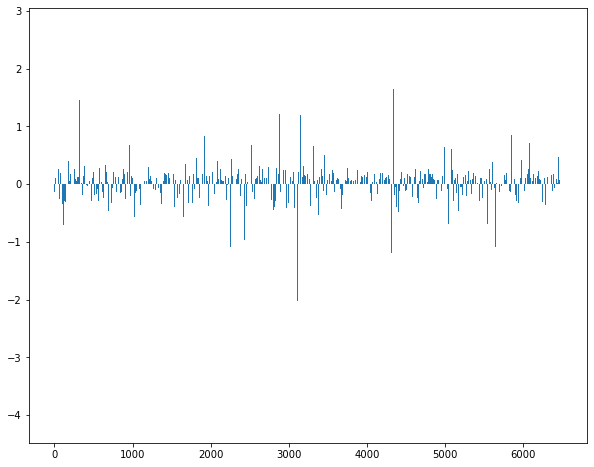
참고
군산대 감성분석 https://github.com/park1200656/KnuSentiLex
KoNLPy https://konlpy-ko.readthedocs.io/ko/v0.4.3/morph/
감성분석 https://cyc1am3n.github.io/2018/11/10/classifying_korean_movie_review.html
https://hyemin-kim.github.io/2020/08/29/E-Python-TextMining-2/